
From time to time the University Archives finds copies of departmental websites stored on CDs or DVDs as directories of html and other associated files. These websites are usually no longer available on the web. When we receive CD/DVDs from University departments, the files are carefully copied from the optical media (a relatively unstable storage medium) and deposited with our repository which is designed specifically for digital materials preservation. However, accessing a website as a directory of individual files rather than web pages in a browser leaves something to be desired. The content might be available, but the use is very different than what was originally intended. Additionally, from an archival standpoint we would like all archived websites to be stored in the WARC file format (an international standard).

In reviewing these items in our collections last year, I began to wonder if it would be possible to temporarily host the websites again. Once hosted online, we could crawl the website with Archive-It, which is the tool we use for website archiving. This method would allow us to provide access to the webpages as a site, connect the websites with the rest of our archived website collections, and generate a WARC file copy of the site’s contents. Luke Aeschleman, then of the library’s software development department, helped me with this project by creating a tool, ROWR, to clean up links and prepare for hosting the site.
ROWR prompts the user for a directory of website files as well as appropriate actions for modifying or removing links. ROWR creates a copy of the site prior to making changes so it is possible to reset and start over, if needed. ROWR also keeps track of the files and folders it has scanned, so it is possible to stop and continue review of the site later.
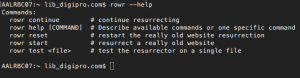

ROWR essentially produces a website that has a new artificial URL to facilitate temporary hosting of the website through a library server. This URL is then added to the Archive-It application and we run a standard crawl of the site. Once the crawl is tested and finalized, we take the website down from the library server.
We tested this approach with two websites. Overall the process works fairly well, but I did come up against some unique collection management and description needs. For example:
- Do we need to keep a copy of the files from the CD/DVD or can we discard it and just use the Archive-It version?
- The crawl date in Archive-It is completely different from the date the website was created and originally used. How should we represent these dates to users in metadata and other description?
- ROWR is changing the content and we are creating an artificial URL, so how do we communicate this to users and what would they want to know about these changes?
- It can be time consuming to use ROWR and clean-up all the links.
I decided that we should keep the copy from the CD/DVD available in the repository as it is representative of the original website and the verison in Archive-It contains an artificial URL. To address the other issues we added some language to finding aids:
“An alternative version made for access is available here. This website was transferred to the University Archives on optical disc. To aid preservation and access the website files were temporarily re-hosted online and archived with Archive-It in 2017.”

In Archive-It, I also created a URL group (“website cd archives”) for the websites that were part of this test project in an attempt to set them apart from our typical web archiving work. I’ve not yet found a satisfactory way to provide context for these website in the Archive-It access portal with Dublin Core metadata, but I hope that the group tag can be a clue that more information exists if a user were to ask us.
These two approaches to description are likely not the permanent solutions to the collection management challenges, but it is a starting point that provides an easier way to access these particular websites online. A future project for us will be to assess metadata description in Archive-It for all of our archived websites.
ROWR is in an early iteration and is not being actively developed at this time, but you can find the code on the UNC Libraries’ GitHub. In the months since we wrapped up this project in the summer of 2017, the Webrecorder team introduced a tool called warcit. The tool can transform a directory of website files into the WARC file format. The resulting WARC file could then be accessed in the Web Recorder Player application. This new tool is something else we’ll be exploring as we continue to improve procedures for the preservation and access of website archives transferred to us as file directories.
2 thoughts on “Behind the Scenes: Introducing Really Old Website Resurrector (ROWR)”