
On May 22, I participated in an Archive-It training webinar on describing archived websites. The following is a summary of my short presentation on the Wilson Special Collection Library’s approach to describing archived websites in finding aids.
Special Collections has been archiving websites with Archive-It since 2013. Our Archive-It account is spilt into collections that reflect our five main collecting units as well as one collection for the UNC at Chapel Hill Art Library. Some of our collecting units use catalog records to describe archived websites, but my presentation is focused on the finding aid side of the house and uses examples from the University Archives collection.
What makes describing websites unique?
In many ways, our approach to archived website description lines up with existing archival finding aid practices. However, there are some ways that archived websites are unique from other materials. For example, date can be tricky. Do we describe the date we archived the website or try to assign some kind of creation date? Our technical services team opted for describing the date we started archiving a website rather than trying to assign the website a date of use or creation. Other challenges are the recurring nature of “crawling” websites, frequently changing content, URL changes and redirects, the differing frequencies used to archive different websites in our collections, and the technical limitations and incompleteness of some archived websites.
Case Studies
We have some consistency in our approach, but we don’t have written documentation yet. The following examples are representative of our approach as well as a couple newer things we have tried more recently.
Archive-It Collection level description
- The first example is a finding aid for the University Archives’ Archive-it collection. The finding aid was created in 2013 and serves as a blanket entry point and general description of all URLs in the collection. I think this is a helpful finding aid to have, but the University Archives collection has grown a lot since 2013. One improvement might be adding series to this finding aid that describe groups of related URLs in the collection. The additional description will help the finding aid show up in more searches. It would also provide users with more access points rather than just being transported directly to the entire (very long) list of URLs in our collection.

URL level description
- The second example is adding description of individual URLs to finding aids. This style of description is pretty standard across manuscript collecting units and was implemented broadly by our technical services team in 2013-14. Typically, these URLs were selected for archiving because we already had a collection for the person or organization. When adding individual archived websites to finding aids, we link to the Archive-It “calendar page” that shows each of the dates we archived the URL. The description also provides the URL, the first crawl date by month and year, and a brief description of the live website.
- This approach works well. One way I’d like to iterate on this approach is to figure out how best to represent the incomplete nature of archived websites in the finding aid. The description of the site describes the live website features and content, but the archived version may be different based on how often we archive it or it may have elements missing due to technical limitations of web crawlers.
- Example:
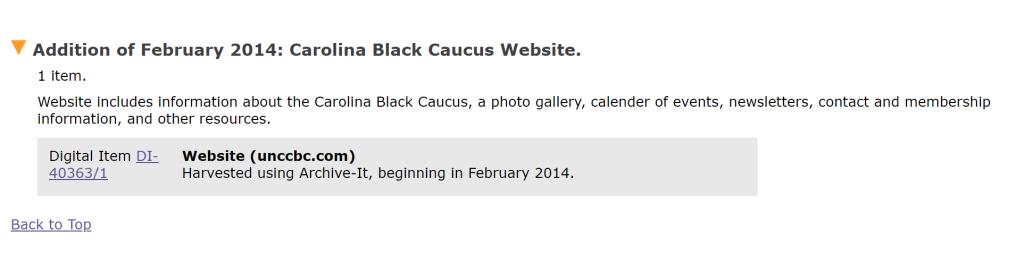
Group of related URLs description
- A third way we’ve represented archived websites is by creator groups and this is a slightly newer approach for us. Instead of listing individual websites on this finding aid, we added one link to the group of URLs created by the student organization. We could have done item level and that might allow for better description of the URLs given that each is quite different (e.g. a Facebook event page vs. Email newsletter vs. a website). But linking to a group of URLs does fit more closely to traditional archival description practices that focus on aggregate rather than items. We’ll have to continue to think about how to handle the donation or selection of several websites by one creator in our descriptions.
- Example:

Intersection of legacy media and websites
- The last example is really different from our other archived websites. Last year I worked on a project with a colleague to deal with website directories given to UA on optical media (I wrote about it on the blog here). These sites are no longer live on the web. We essentially re-hosted the website, gave it an artificial URL, and crawled it with Archive-It.
- One of the questions we had was how to best describe these websites. In order to re-host and archive the sites with Archive-It we had to use an artificial URL and the crawl date is very different from the creation/use of the site. Additionally, the directory of files from the DVD had already been ingested to the repository a couple years ago. We needed to make some connections between these factors.
- We decided to keep a link to the repository, note the DVD identification number, link to Archive-It, and explain a bit about the process to re-host the site.

Next Steps
Our staff last talked about this work in 2013-14 when we first started using Archive-It, so our best next step is to revisit this topic as a group and figure out how we can iterate on our current approaches to meet the unique description challenges posed by archived websites. I had the pleasure of participating in the OCLC Web Archives Description working group in 2016-17 and the guidelines produced by the group will be a helpful resource in this discussion. Documentation of our practices for describing websites will be an important addition to our existing documentation for description of born-digital materials in archival finding aids. I’d also like to use more metadata in the Archive-It access interface. The OCLC WAM guidelines can help with that as well.
You can use and explore our archived website collections online through our Archive-It access portal.
One thought on “Behind the Scenes: Describing Archived Websites”